How can you typically use two channels?
1 Like
Which one do you use?
Currently using the Wizard 13B model.
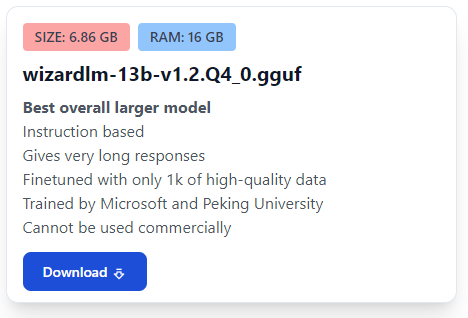
Using it with GPT4All - their LocalDocs feature makes it super easy.
1 Like
Cool!
I have many different documents that are (in some cases) highly confidential. in various formats (XLS, DOC; PPT, PDF etc.) and in various languages (Dutch, German, English and French).
Maybe you can answer some questions?
- is processing done really locally? No confidential information should leave my network. Ever!
- Can it process al those file types?
- Can it process different languages?
- Can you say anything about performance? My LLM machine would have an NVIDIA 3070, quite recent i7 and 32GByte RAM. Harddisk space is about 200TB in my local network, so I don’t expect challenges

My A channel hook up with all my pedals, and my B channel is connecting to my GT 1B.
I used to just connect 2 basses directly to the pedal to A/B it.

1 Like
Yep! That’s exactly why I started using it, didn’t want to leak private data. Note that there is an option to enable contributing to a public datalake. It’s disabled by default, but obviously would want to verify that it is indeed disabled.
Not currently. It can do .TXT, .MD, .RST, and .PDF. Easy enough to convert to PDF if needed. I primarily use PDF, though it has been fun to grab closed caption files from long YouTube videos and then interrogate those.
I’d want to experiment a bit before confirming. It certainly supports multiple languages in the chat. Presumably it can ingest data in various languages as well, but again I would want to experiment to be sure.
I’m using an i7 which is quite old, albeit with an NVIDIA 4080. The 8G VRAM is going to be your constraint, although in that case you can either use the 7B model instead of 13B or split the model between VRAM and DRAM. The latter option will slow it down considerably.
Does “slowing down” mean: slowing down while prepocessing all files
or does it mean: slowing down the answering latency of a request?
1 Like
This is a good use case for them - if you can control the quality of the inputs and are careful with the queries then at least it could be a very nice interface to document search and cross indexing.
1 Like
I’m not sure on the processing of the LocalDocs, but certainly it would impact inference speed when using the model. It tries to load the whole thing into VRAM.
Mind you, it’s possible to run it without any GPU whatsoever, and just use CPU and DRAM.
At the end of the day, there’s no cost to it, so well worth the effort to tinker if you’re curious. I started with a 7B model, and even run that on my laptop nicely, while the 13B model I run on my home PC with the nicer GPU.
1 Like
Yep! I’ve found it useful as a first pass in doing market analysis and sifting through a bunch of industry analyst reports that I’ve gathered when planning product releases. I verify everything of course, but it’s a good way to get a quick head start.
Now I’m going to have to find a practical bass application for it as an example, LOL! ![]()
1 Like
Roughly how long are you seeing typical queries take? I am guessing a long time ![]()
The online ones are quite slow but then again are running on datacenter machines optimized for power usage and scale and not speed.
Here’s an example. It’s not terrible, really, for running it on an old PC with a good GPU. I sped up my typing, but the response is real time.

I can’t share any of the RAG examples I currently have, but I’ll find an example to use. Speed is similar.
1 Like
Providing it tells you the references docs!
Like FEA, they’re good tools but you already need to know what the answer should be ![]() The image AI is like that too… you can make some great art if you’re not too particular about what you’re getting and you already know what “good” art is so you can eliminate all the garbage that you get
The image AI is like that too… you can make some great art if you’re not too particular about what you’re getting and you already know what “good” art is so you can eliminate all the garbage that you get ![]()
FEA and CFD are where my thoughts on LLM AI as well. Increased productivity for skilled users, and tools that are worse than useless for rise without the training and background to understand what they’re looking at.
1 Like